この前,Convolutional Neural Networksのサーベイを発表した時,
論文(コンピュータサイエンス系)の探し方を随分と聞かれたので,まとめてみました.
主にFeedlyでarXivみるっていう話ですけど,
他の情報収集元もあげてみます.
Feedly
Feedlyは,RSSリーダです.
もちろん,論文サーベイ以外にもRSSリーダとして使えるので,おすすめ.
(ホームにあるFollowボタンは,Feedlyのこのブログの購読ボタンだったりする)
arXiv
arXiv(アーカイヴ、archiveと同じ発音)は、物理学、数学、計算機科学、量的生物学、Quantitative Finance, 統計学の、プレプリントを含む様々な論文が保存・公開されているウェブサイトである。論文のアップロード(投稿)、ダウンロード(閲覧)ともに無料で、論文はPDF形式である。1991年にスタートして、プレプリント・サーバーの先駆けとなったウェブサイトである。大文字の X をギリシャ文字のカイ(Χ)にかけて archive と読ませている。 arXiv - Wikipedia
私がよくチェックする機械学習やコンピュータビジョン界隈では,arXivの存在はかなり知られていて,大きな国際会議に投稿されたものがアップロードされていたりします.
webに論文をあげるので,後から修正や補足が出来る様になっていることも,良いポイントだと思います.
FeedlyでarXivをトラッキングする
簡単にFeedlyでarXivの好きなサブジェクトを追いかける方法をまとめます.
(あらかじめFeedlyの会員登録がされている体で話を進めます)
例として,Computing Research RepositoryのArtificial Intelligence (cs.AI)をFeedlyに登録してみます.
(CoRRのサブジェクトは全部でこんなにある)
-
arXivにアクセス
-
Computing Research RepositoryのArtificial Intelligence (cs.AI)へアクセス

-
URLをコピーして置く

-
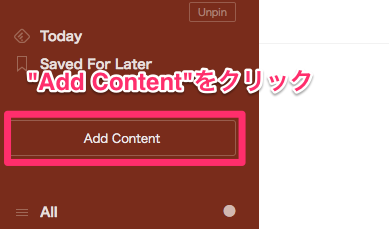
Feedlyを開いて Add Contentをクリック
-
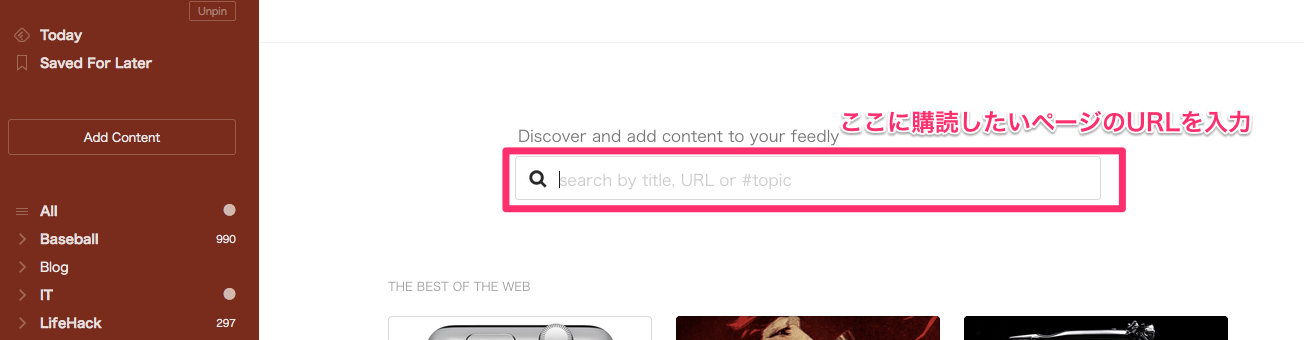
検索窓に購読したいページのURLを入力

-
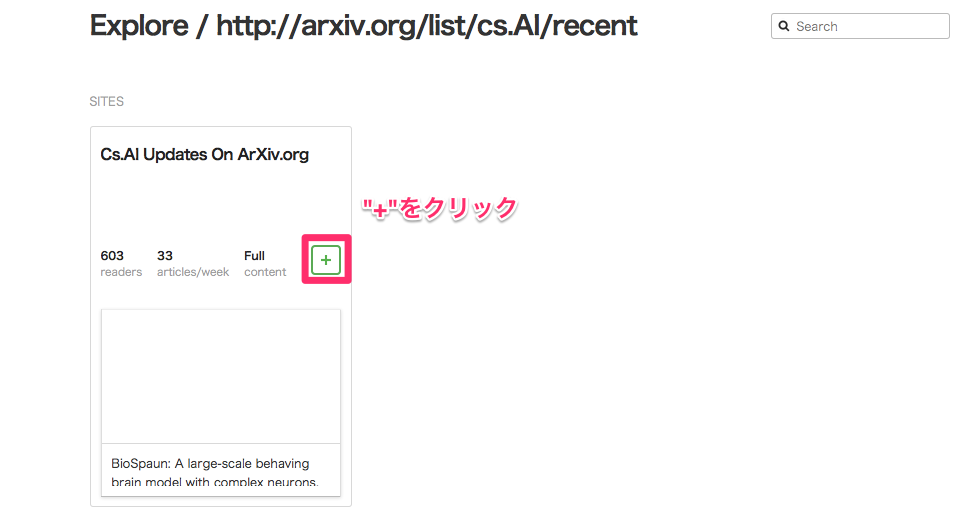
+を押してFeedlyへの登録画面へ
-
追加するコレクションを選んでAddを推す

これでFeedlyで論文がトラックできるようになっているはず.
他のサブジェクトを登録したい場合はさっきまでの作業を繰り返せばOKです.
こんな感じ.
もし,"by ~"の左に数字が出ているときはそれは「engagement」を示す数字です.
その論文がどれくらいバズっているかわかるので,私がFeedlyを使う理由の一つでもあったりします.
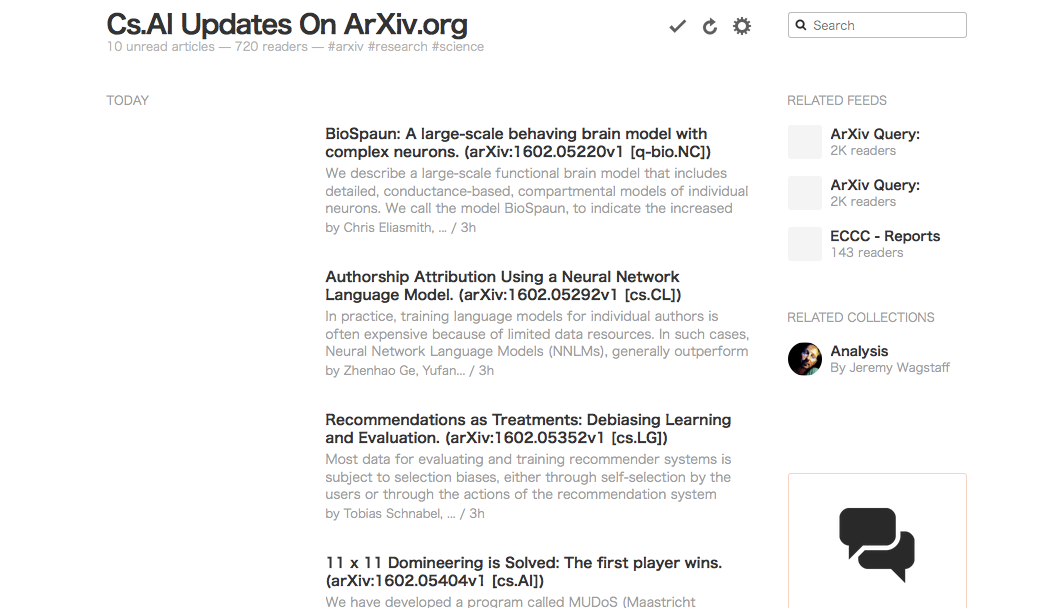
記事をクリックすれば,アブストラクトも読める!

"Visit Website" をクリックすれば,arXivの該当ページに飛んで,pdfやbibtexのファイルを入手出来ます.やったね!

Redditで技術系のスレッドを見つける
arXivの話だけだと寂しいので,他の情報収集元を言うと,
Redditの機械学習系の議論はたまに目を通します.
なかなか面白い議論のときもあれば,過疎ってるときもあるけど…
reddit(レディット)は英語圏のウェブサイト。ニュース記事、画像のリンクやテキストを投稿し、コメントをつけることが可能。ウェブサイトへのリンクを収集・公開するソーシャルブックマークサイト。ニュース記事、画像などの紹介や感想募集のトピックを誰でも立てられるソーシャルニュースサイトでもあり、トピックについてのコメントを誰でも書き込める電子掲示板の一種でもある。 reddit - Wikipedia
ML@REDDITをフォローすると,
機械学習系のスレッドがどんどん流れてくるので,チェックしています.