第12回ファジィ学問塾
11月26日〜27日の1泊2日の日程で, 第12回ファジィ学問塾 が行われ,参加してきた.
参加者は21人でそのほとんどが学生(学部〜博士課程)だった.
参加した人みんながDeep Learningを研究テーマにしているわけでなく(むしろ少数派),
信号解析とか,ロボット制御とか,情報系ではない分野など,とても多様性があって面白かった.
今回は「Deep Learning」がテーマということで,講師の先生方からBack Propagationの基礎から
実際にTensorFlowを使って手を動かすまでレクチャーがあった.
中でも,Googleの佐藤氏によるGoogle社内でのDeep Learningに関する取り組みは,
さすが世界でも飛び抜けて研究開発を進めている企業の一端が垣間見えた感じで,
これは計算機を沢山まわさないといけない分野では勝ち目ないなと痛感させられた.
しかし,ユーザ目線で見てみると,先日のニューラル翻訳をはじめとして,
これまで以上に便利で新しいサービスが出て来そうで,わくわくする.
日程の後半戦は主に,手を動かす演習で,
- パラメータを変更することによる性能変化を調査せよ
- 学習器がどのような特徴量を用いて識別しているか調査せよ
- 自由課題
のうち2つを選択して,4〜5人の班ごとに取り組むというものだった.
やったこと
そんなわけで,私の班では最初の2つを選択して,余力があれば自由課題にも挑戦するという作戦に.
私は,Convolutional Neural Networks(CNN)の特徴量解析ということで,
任意の入力画像を特定のクラスに分類されるように最適化する手法を実装してみた.
Inverting Visual Representaion
今回実装した手法は,「Deep Dreamのアレ」というと界隈の人には伝わるけども,
ちゃんというと,「Inverting Visual Representaion」と呼ばれることが多い.
手法自体は, ある画像Xを学習済みCNNモデルyに投げて得られる結果y(X)と任意の教師ラベルdとの誤差e(f(X), d)を最小化するように, 画像Xを最適化するというものだ.
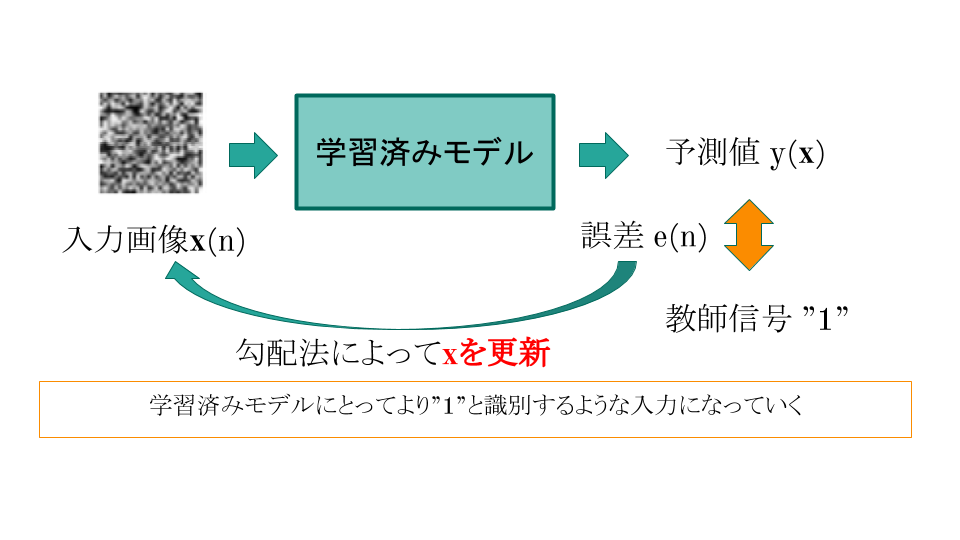
発想的にはそんな最近のものではないと思うけど,文献でいうと,
で今の話について触れられている.
最近の文献であれば,
- K. Simonyan, et al. Deep Inside Convolutional Networks: Visualising Image Classification Models and Saliency Maps. arXiv: 1312.6034, 2013.
- A. Dosovitskiy, et al. Inverting Visual Representations with Convolutional Networks. arXiv: 1506.02753, 2015.
あたりで,一般物体認識課題を学習させたネットワークでの実験結果が報告されている.
(Simonyanらの文献は2節に,Dosovitskiyらの文献では誤差関数に正則化項をつけることで人間により見やすい画像を生成している)
さらに,この原理を応用して「Adversarial Examples」と呼ばれる,「ネットワークを間違えさせるデータ」を生成する研究も進んでいる.
このへんの特徴解析あたりの話は,前に某所で発表した資料でも触れている.
結果
前置きが長くなったけど,実際に演習でMNISTをそこそこ(テストデータに対して98%くらい)学習させたネットワークについてやってみた結果がこれ.

一様乱数を入力にすると,数字によってはそれっぽく見えないこともないけど,
全体的にとてもよく上手くいっていない.
入力画像自体はかなり収束しちゃっていたので,
そもそももっとネットワークを学習させておくべきだったみたいだ.
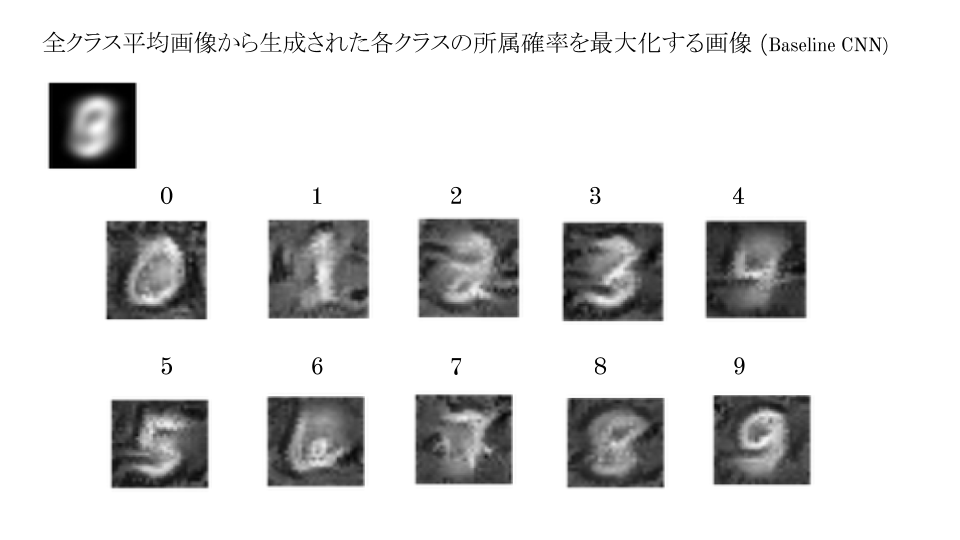
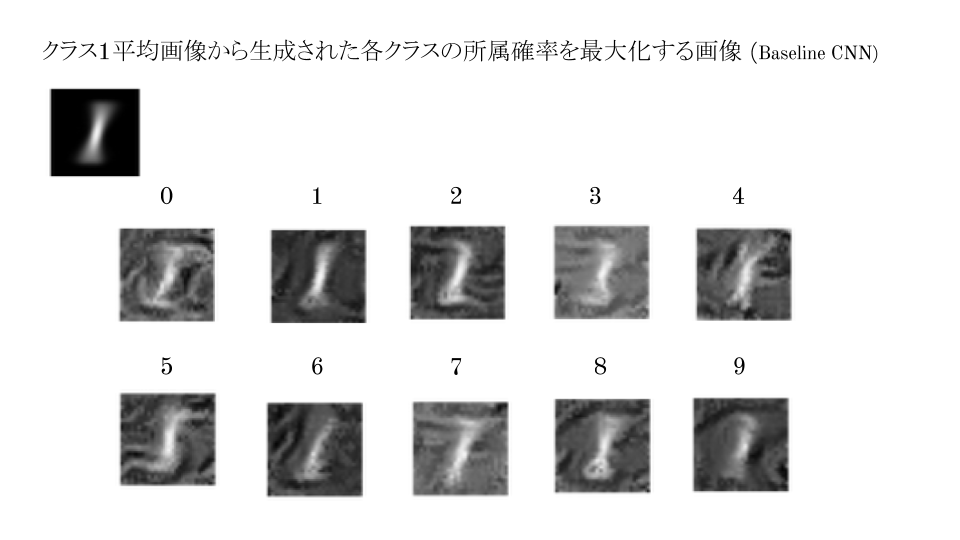
一方で,学習画像全体の平均画像や,学習画像中に含まれる1の平均画像を入力した場合ついては,
面白い結果が得られている.
学習画像全体の平均画像を入力した場合は,それぞれの数字に見えるようになっているし,
1を他の数字画像にしてもらったときに,
どういう風に画像が変わったかを観察するとCNNがどんな特徴で識別しているか読み取れる.
最終的には,これを更に発展させた内容まで持っていって見たかったけれども,時間がなかったので断念….
コード
一応試せるようにコードを公開しておいた.
ちなみに,様々な問題があってTensorFlowではなくChainerで実装した….許して欲しい….笑
DaikiShimada/soft-seminor: Inverting Visual Representation in Fuzzy Seminor 2016
TensorFlowでやってみたい人向けには,アイドル画像識別で似たことをしている人がいるので,
参照してみるとよいかも.
TensorFlowで顔識別モデルに最適化した入力画像を生成する - すぎゃーんメモ
感想
最初にも言ったけども,
もともと情報分野に親しくない人や,Deep Learningに触れたことのない参加者が多かったので,
そういう人にはややハードな日程だった気もする.
でもこういう風に短期間にドカッと知識を叩き込むのもいいかな.
全国からくる参加者とも交流できるし,講師陣,サポートしてくださる先生方とも交流できる.
そういう意味では,学会がこういう場を提供してくれるのは貴重だと思うので,
もし来年も同じような催しがあれば,興味ある人は参加してみるといいかも.
参考文献
- D. Erhan, et al. Visualizing higher-layer features of a deep network. Technical Report 1341, University of Montreal, 2009.
- K. Simonyan, et al. Deep Inside Convolutional Networks: Visualising Image Classification Models and Saliency Maps. arXiv: 1312.6034, 2013.
- A. Dosovitskiy, et al. Inverting Visual Representations with Convolutional Networks. arXiv: 1506.02753, 2015.
- I. Goodfellow, et al. Explaining and Harnessing Adversarial Examples. arXiv; 1412.6572, 2014.
- Deep Learning のトレンドについて喋ってきた | Futon note
- TensorFlowで顔識別モデルに最適化した入力画像を生成する - すぎゃーんメモ